现象与应急
下午6点,突然发现监控大盘,核心服务耗时上涨了(400ms -> 800ms), 群里通知小伙伴看日志,发现有 "xx 数据查询线程池拒绝,激活线程数:50,最大线程数:50,排队数:200" 的日志,怀疑下游耗时上涨把线程池打满了,看下游耗时,在17:00 - 17:30 确实有明显的耗时上涨,部分最大耗时到了3s, 但是下游恢复了,我们却还没有恢复。
因为耗时上涨,同时如果机器一直拒绝的话,会影响首页运营位相关的功能,所以先考虑进行了重启操作,结果,重启之后,耗时居然直接飙到了3s以上,系统功能几乎不可用了,之后,进行扩容,不分限流,也不管用。
后来进行怀疑是有循环依赖问题,导致重启加剧了系统阻塞,所以,先紧急对系统进行了限流,同时进行了动态线程池的调整(线程池大小从50 -> 120,这里之前做了动态配置,直接修改就生效了),才终于恢复了。
疑问点
1、为什么17点30 - 18点00下游耗时恢复了,线程池打满却没有恢复;
2、为什么重启之后,马上又被打满了,而且重启之后,效果还更差,直接导致系统block住了;
原因排查
1、jstack 导出了堆栈,统计对应的线程池,发现该线程池所有线程都执行到169行就wating了,同时看代码里面有join(jdk 8里面是没办法)
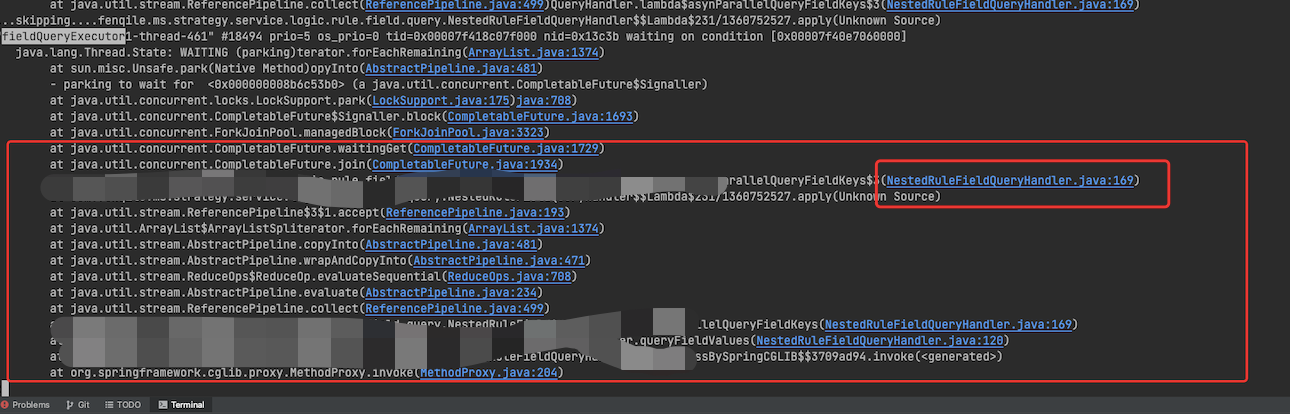

2、arthas trace和watch看对应堆栈的执行,没有输出(证明线程是彻底卡死了)– 这里可以解答疑问 1
3、期间因为还有应用overload的告警(dubbo线程池打满了)
从以上两点基本上可以断定是跟这里的join代码有关了
4、join卡死的原因:
- 流量变大 + 下游耗时增加,导致线程池被打满了
- 没有超时时间 , 拒绝策略问题,导致线程卡死
只有以上两个问题,下游恢复,重启是能恢复的
5、重启不恢复,反而导致故障加剧的原因,因为有循环依赖,所以出现了以下场景:
- 其他机器的流量上升;
- dubbo线程池被打满;(部分机器)
- 字段线程池被打满;(部分机器)
故障时序
1、发生的时候已经有部分机器字段线程池打满了;(监控可以大概证明,之前耗时已经翻倍了)
2、下游耗时增加,导致更多机器字段线程池打满;(监控可以说明)
3、重启,增加了流量,导致部分机器的dubbo线程池打满(超过50qps);开始死循环;(监控可以看出来) – 这个可以解答上面的疑问 2
4、dubbo被打满,导致更多的字段线程池被打满,从而性能更差;
启思
1、类似的问题,怎么应急, 以及快速排查
- 流量变大 + 下游耗时增加,导致线程池被打满了 (扩容,主动熔断降级,流量不大的情况下,还是要先考虑重启(先扩容,再重启));
- jstack dump出线程堆栈,看是否有异常;
2、系统建设上有哪些注意点,避免出现类似的问题
- 超时时间 & 熔断机制(可以降低影响,最少不会卡主)
- 线程池尽量不共用(特别是有依赖的)
- 线程池的拒绝策略(可以降低影响,最少不会卡主)
- 避免循环依赖
- 限流措施
3、更近一步的思考
本质上是资源不足
已完成优化
1、线程池的拒绝策略修改为抛出异常;
2、打破资源的循环依赖;(dubbo线程池隔离)
3、线程池隔离;
4、future获取设置超时时间;